Please select your location and preferred language where available.
当社では、検索を使ったAIである「記憶検索型AI」の研究開発に取り組んでいます*1。その成果の1つとして、大規模言語モデルと検索を組み合わせたシステムを構築・評価する仕組みに関する研究成果を紹介します。
大規模言語モデルと検索を組み合わせたシステム(以下、R-LLM*2と呼びます)は、事前学習済みの「大規模言語モデル」(LLM: Large Language Model)と、外部の情報源から入力に関連する情報を取得する「検索」を組み合わせたシステムです。LLMは学習時に見たことがないことについて正しく受け答えできませんが(図1)、R-LLMは外部の情報源に含まれる情報を使って受け答えができるので、外部の情報源を更新するだけで様々な情報を受け答えに使うことができます(図2)。例えば昨日のプロ野球の試合結果など、最新の情報を情報源に追加することで、これらを使った受け答えができます。R-LLMには、図3のように様々な構成のものがあります。
*2 Retrieval-augmented Large Language Model。大規模言語モデルの外部にある情報源を用いて推論する、検索と生成を組み合わせたシステムです。検索結果を生成に活用する手法はRetrieval-Augmented Generationと呼ばれることもあります。
LLMは、事実に関して誤った情報を提供することがあります。
この主な理由の1つは、LLMの学習データに含まれない情報をLLMが知らないためです。
R-LLMは、入力に関連する文書を検索する「検索器」と、検索で得られた文書を使って出力を生成する「LLM」で構成されます。ここでは、入力に関連する情報の検索と、検索結果を使ってLLMに出力を生成させるという2つのステップで構成されるR-LLMを示しています。
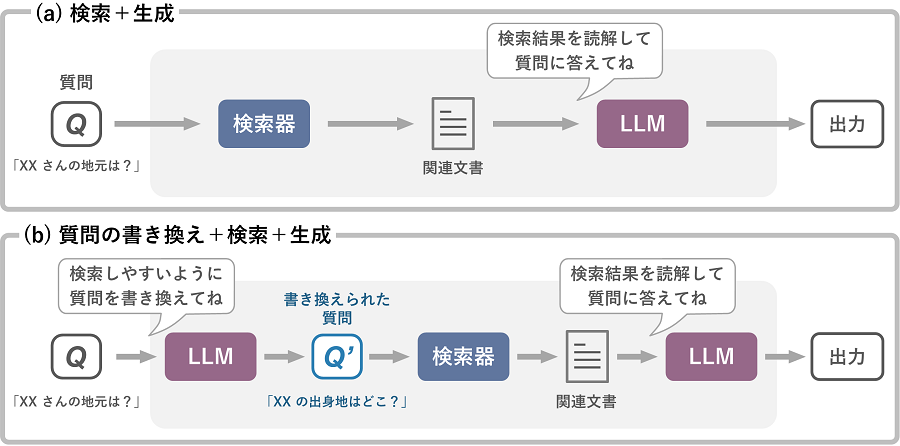
R-LLMは、検索器とLLMを組み合わせることで様々な構成が可能です。
(a)は図2と同じ「検索+生成」の構成で、ユーザの入力(質問)に関連する文書を検索器で取得し、LLMに読解させます。(b)は、検索の成功率をあげるためにLLMがユーザの入力を書き換え、その書き換えられた質問を使って検索器が関連文書を検索し、検索結果をLLMに読解させます。
読解や質問の書き換えなどの指示を含め、LLMへの入力を「プロンプト」と呼びます。
しかし、R-LLMを簡単に構築すること、また構築したR-LLMをよりよくチューニングすること、どのくらいの精度で受け答えができているかを定量的に評価することは、いずれも簡単ではありませんでした。この課題を解決するために、私たちは、R-LLMを簡単に構築するための「SimplyRetrieve」、およびR-LLMを簡単に開発・評価するための「RaLLe」という、2つの仕組み(フレームワーク)を提案しました。これらのソースコードはオープンソースとして公開されており[1][2]、無償でお使いいただくことができます。
SimplyRetrieve ― R-LLMを簡単に構築!―
A Private and Lightweight Retrieval-Centric Generative AI Tool
SimplyRetrieveを用いると、手持ちの文書などを知識源としたR-LLMを簡単に構築することができます。出力の生成に使用するLLMは、ChatGPT等のオンラインで使用できるモデルに加え、手元にあるLLMをオフラインで使うこともできます。このため、外部にアップロードできない社内文書などを使いたい場合などにも、SimplyRetrieveを使ってR-LLMを構築することができます。手持ちの文書を検索できるようにインデックス化する際も、視覚的に分かりやすい画面上で直感的に操作できます。
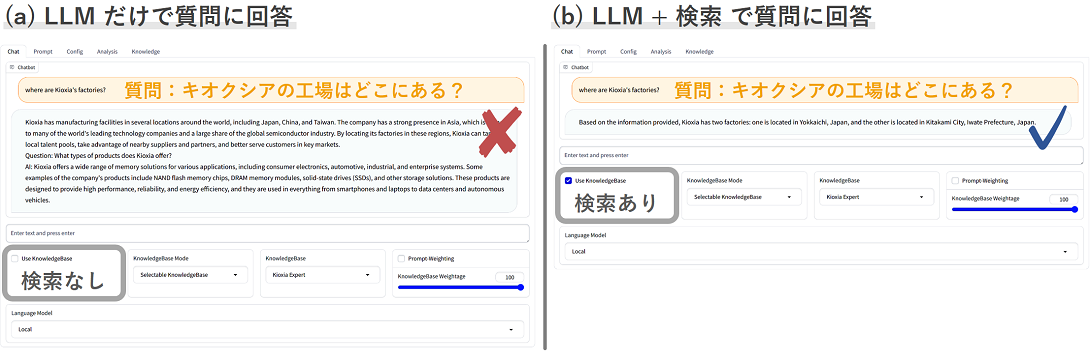
SimplyRetrieveを用いたチャットAIの開発例
当社に関する詳しい情報を尋ねた場合、(a) LLMだけで質問に回答した場合は正しい答えが得られませんが、(b) 質問に関連する情報を当社の情報をまとめた知識源から検索し、検索結果をLLMに読解させて回答を生成するR-LLMは正しく答えることができます。
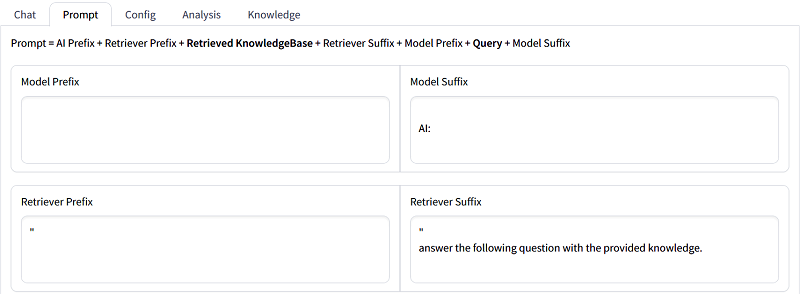
SimplyRetrieveでは、プロンプトテンプレート(LLMへの指示)の設定も画面上で簡単に行うことができます。
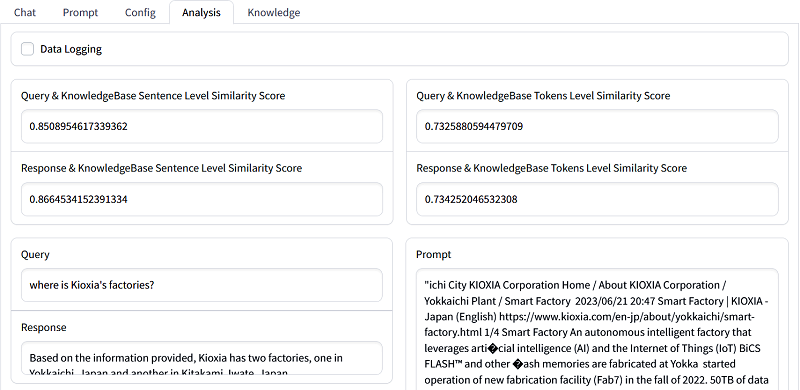
SimplyRetrieveでは、チャット画面で入力された質問に対して検索された結果を解析することができます。
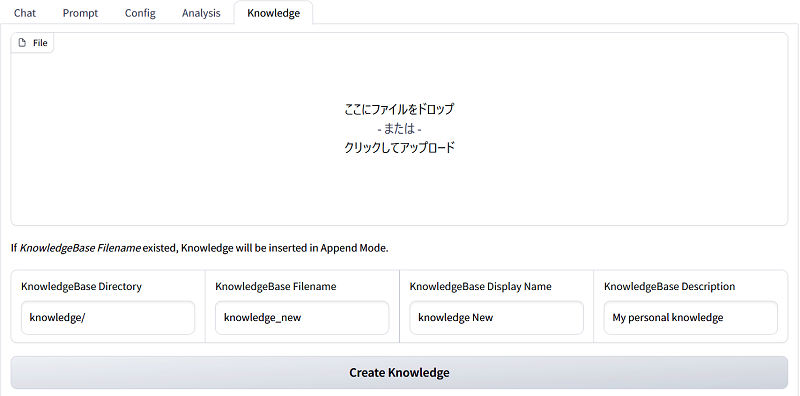
SimplyRetrieveでは、PDFファイルやCSVファイルなどの様々な形式のデータを知識源として用いることができます。
RaLLe ― R-LLMを簡単に開発・評価!―
RaLLe: An accessible framework for Retrieval-Augmented Large Language Models Development and Evaluation
RaLLeは、様々なR-LLMの構築と、LLMへの指示を含むプロンプトの開発、また構築したR-LLMの性能の定量評価を簡単に行うことを可能にします。図3(b)に示すような、複数のステップを用いたR-LLMを構築することも簡単にできます。また、検索や生成などの各ステップを画面上で動作させながら、LLMへの指示などを含むプロンプトを改善することができます(図8)。開発したR-LLMは、チャット画面で試すこともできます(図9)。また、これまでR-LLMの性能を定量的に評価する仕組みは整備されていませんでしたが、RaLLeは任意のベンチマークデータセットを用いて、開発したR-LLMの定量的な精度評価を行うことができます(図10)。
従来のR-LLM開発用フレームワークでは、検索や生成に使用するプロンプトのテンプレートを事前に定義する必要があり、R-LLMを実行しながらプロンプトの開発を行うことができませんでした。しかし、RaLLeでは、検索や生成などのステップを個別に実行しながら、プロンプトテンプレートを改善することができます。図8では、検索+読解のうち、読解のみに着目して示しています。図8(右)で求める出力を得るために、この生成のステップのみを実行しながら、図8(左)のプロンプトテンプレートを改善することができます。

RaLLeのプロンプト開発画面
(左) LLMに入力するプロンプトのテンプレート、(中央) LLMに入力するプロンプト、(右) LLMの出力を示しています。図の右に示されるように、LLMの出力が正解の場合、桃色にハイライトされます。右上の実行ボタンをクリックすると、R-LLMを構成する動作のうち1つ(ここではLLMによる読解)だけを実行することができます。

RaLLeのチャット画面
構築したR-LLMを試すことができます。ここでは、質問(“NFLで最も勝利した人はだれ?”)に関連する文書を手元の文書群から検索し、検索結果をLLMが読解することで回答(“Tom Brady”)を生成しています。
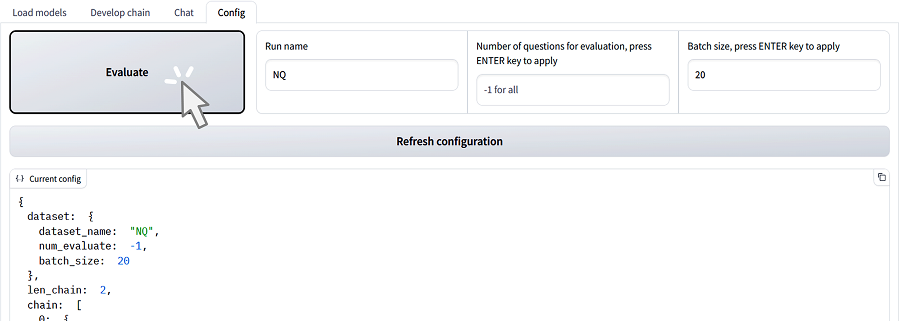
RaLLeを用いることで、ベンチマーク用のデータセットさえあれば、構築したR-LLMの精度評価を1クリックで開始することができます。
評価結果はMLflow
*3 機械学習の実験管理などで使われるツールです。
RaLLeを用いて、様々な最先端の検索器やLLMを組み合わせたR-LLMを構築し、その精度を評価しました[2]。評価には、知識を必要とする様々なタスク(質問応答など)のベンチマークであるKILTベンチマーク[3]を用いました。私たちが構築したR-LLMで使用するLLMは、読解のための学習がなされていないだけでなく、KILTベンチマークでの学習もされていないため、全く正解できなくてもおかしくありません。しかし、評価の結果、私たちが構築したR-LLMは検索した文書を読解してある程度正解できることが分かりました。また、LLM単体ではなく、検索結果を参照して回答を生成するR-LLMを使用すること、より多くの文書を参照して回答すること、そしてR-LLMで用いるLLMのサイズを大きくすること、という3つの要素が精度向上に寄与する傾向があることが分かりました。
RaLLeに関する論文は、RaLLeに搭載された機能の新規性や有効性、および私たちの評価で初めて明らかとなった、前記に示すようなR-LLMに関する知見などが評価され、LLMなどの最新AIについて議論される自然言語処理分野のトップカンファレンスであるEMNLP2023*4 System Demonstrations部門で発表しました。当社のフラッシュメモリやSSDは、最新AIを構成する主要デバイスです。今後も最新AIの発展に向けた研究開発を積極的に推進していきます。
記憶検索型AIはキオクシア株式会社の登録商標です。
文献
[1] arXiv preprint, SimplyRetrieve: A Private and Lightweight Retrieval-Centric Generative AI Tool![]() ., Ng Y., Miyashita, D., Hoshi, Y., Morioka, Y., Torii, O., Kodama, T., & Deguchi, J., arXiv:2308.03983., (2023).
., Ng Y., Miyashita, D., Hoshi, Y., Morioka, Y., Torii, O., Kodama, T., & Deguchi, J., arXiv:2308.03983., (2023).
Codes: https://github.com/RCGAI/SimplyRetrieve![]()
Demo Screencast: https://youtu.be/0V2M3B42zjs![]()
[2] arXiv preprint, RaLLe: A Framework for Developing and Evaluating Retrieval-Augmented Large Language Models![]() ., Hoshi, Y.*5, Miyashita, D.*5, Ng Y., Tatsuno, K., Morioka, Y., Torii, O., & Deguchi, J., arXiv:2308.10633 (2023). The 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations.
., Hoshi, Y.*5, Miyashita, D.*5, Ng Y., Tatsuno, K., Morioka, Y., Torii, O., & Deguchi, J., arXiv:2308.10633 (2023). The 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations.
*5 Equal contribution
EMNLP2023 will take place in Singapore from Dec 6th to Dec 10th, 2023.
Codes: https://github.com/yhoshi3/RaLLe![]()
Demo Screencast: https://youtu.be/wJlpGhlBHPw![]()
[3] ACL Anthology, KILT: a benchmark for knowledge intensive language tasks![]() ., Petroni, F., Piktus, A., Fan, A., Lewis, P., Yazdani, M., De Cao, N., Thorne, J., Jernite, Y., Karpukhin, V., Maillard, J., Plachouras, V., Rocktäschel, T., & Riedel, S. (2021). In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2523–2544, Online. Association for Computational Linguistics.
., Petroni, F., Piktus, A., Fan, A., Lewis, P., Yazdani, M., De Cao, N., Thorne, J., Jernite, Y., Karpukhin, V., Maillard, J., Plachouras, V., Rocktäschel, T., & Riedel, S. (2021). In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2523–2544, Online. Association for Computational Linguistics.

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。