Please select your location and preferred language where available.
当社では、検索を使ったAIの研究開発に取り組んでいます*1。そのうちの1つである、文書検索に関する研究成果を紹介します。
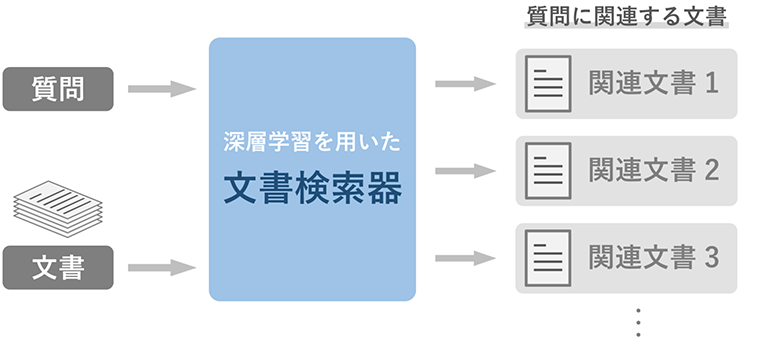
文書検索は、ストレージ等に収められた大量の文書の中から、ユーザの質問に関連する文書を見つけ出すタスクです(図1)。近年、言語に特化した深層学習モデルである「事前学習済み*2言語モデル」は、文書検索のための追加学習*3を行うことで、文書検索器として機能することが知られています。しかし、深層学習を用いたこのような文書検索方法にも、様々な課題があることが分かってきました。
たとえば「XXさんはどこで生まれたの?」のような、質問中の人名(この例では「XX」さん)や地名のような「固有表現」を主要な手掛かりとする検索が苦手であることが判明しています[1]。この課題に関して、これまでは主に「文書検索のための追加学習方法を工夫する」という方向性で解決が試みられてきました。
それに対して私たちは、「事前学習済み言語モデルを追加学習せずに用いることで文書検索の精度を改善する」という、従来とは真逆の発想に至りました。言語モデルの事前学習では、文書検索のための追加学習の時よりずっと大きなデータ量の文書群が使われます。このため、言語モデルは事前学習によって固有表現に関する豊富な知識を持つことができるはずです。その言語モデルに文書検索のための追加学習を行ってしまうと、せっかく持っていた知識を忘れてしまい*4、本来の強みをかえって失ってしまうと考えたのです。しかし、事前学習済み言語モデルを追加学習せずそのまま文書検索に利用する方法は、今まで明らかではありませんでした。
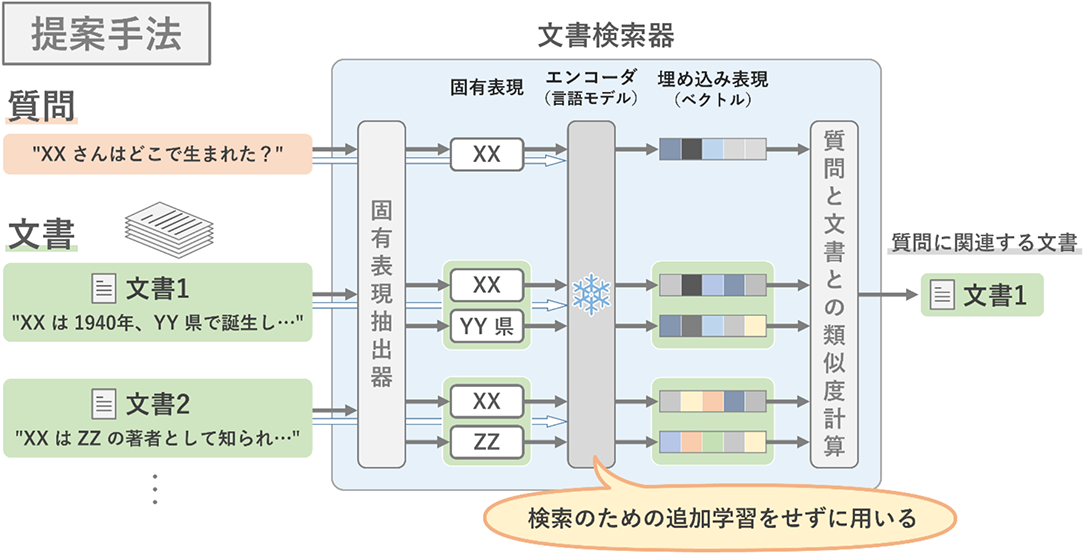
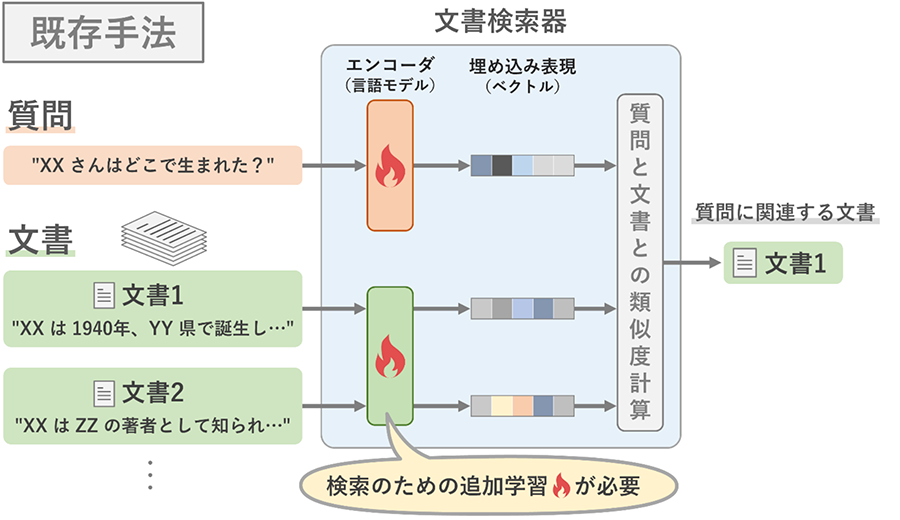
私たちは、事前学習済み言語モデルを追加学習せずにそのまま利用する文書検索手法を発見しました(図2)。言語モデルは、質問と文書から取り出された固有表現を、それらが元あった文章の文脈を反映させた埋め込み表現(ベクトル)にするためのエンコーダとして用いられます。従来手法では質問用と文書用の2つの言語モデルをエンコーダとして追加学習する必要がありましたが(図3)、私たちの手法では質問用と文書用に言語モデルを区別する必要がなく、たった1つの言語モデルで文書検索ができることも特徴です。
この手法の検索性能を、計24の関係性(生誕地、出身校など)からなる、固有表現が主要な手掛かりとなる文書検索データセット[1]で評価しました。その結果、提案手法は最先端の文書検索器(74.5%)に近い検索精度(67.1%)を達成し、また計24の関係性のうち2つにおいて、過去最高の性能を達成することが分かりました[2,3]。既存手法では、例えば医療などのある特定の分野で機能する文書検索器を構築するためには、その分野での検索に特化した追加学習を行うためのデータセットを構築する必要がありました。一方で私たちの手法は、その分野の文書で事前学習された言語モデルさえあれば、追加でデータセットを構築することなく、文書検索ができる可能性を示しています。
本成果は、人工知能分野におけるトップの国際会議の1つであるAAAI-23(the Thirty-Seventh AAAI Conference on Artificial Intelligence)に併設のKnowledgeNLPワークショップ(workshop on Knowledge Augmented Methods for NLP)で発表されました。
*1 「記憶検索型AI」前編 キオクシアのトップエンジニアが開発に取り組む『記憶』を大切にするAIとは?
https://brand.kioxia.com/ja-jp/articles/article26.html![]()
「記憶検索型AI」後編 Internet of Memories:NFTアートから子守りAIまで、「記憶検索型AI」の実装アイデアを探る
https://brand.kioxia.com/ja-jp/articles/article27.html![]()
大容量ストレージを活用した記憶検索型AIによる画像分類技術をECCV 2022で発表
https://www.kioxia.com/ja-jp/about/news/2022/20221102-1.html
大容量ストレージを活用した記憶検索型AIによる画像分類技術の開発
https://www.kioxia.com/ja-jp/rd/technology/topics/topics-39.html
*2 事前学習:自然言語処理では、大規模な文書群を用いて、深層学習モデルに言語に関する知識を学習させます。近年は、ラベル付けなどの加工がなされていない文書群を用いて自己教師あり学習を行うものが一般的です。
*3 追加学習:自然言語処理では、事前学習済みの言語モデルを、文書検索のような特定のタスクを実行できるようにするための追加の学習(fine-tuning)が行われます。追加学習には、特定のタスク専用のラベル付きデータセットが用いられます。(ラベル付きデータセットを構築するのはコストがかかるため)追加学習のためのデータセットの大きさは、事前学習のためのデータセットよりはるかに小さいことが一般的です。文書検索のための追加学習で用いられるデータセットには、質問集とそのそれぞれの質問に関連する文書とのペアが用いられることが多くなっています。
*4 学習済みの深層学習モデルを追加学習すると、以前の学習で得たことをすっかり忘れてしまうことがあります。
文献
[1] Sciavolino, C., Zhong, Z., Lee, J., & Chen, D. (2021). Simple Entity-Centric Questions Challenge Dense Retrievers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (pp. 6138-6148).![]()
[2] Hoshi, Y., Miyashita, D., Morioka, Y., Ng Y., Torii, O., & Deguchi, J. (2023). Can a Frozen Pretrained Language Model be used for Zero-shot Neural Retrieval on Entity-centric Questions? Workshop on Knowledge Augmented Methods for Natural Language Processing, in conjunction with AAAI 2023.![]()
[3] Hoshi, Y., Miyashita, D., Morioka, Y., Ng Y., Torii, O., & Deguchi, J. (2023). arXiv preprint arXiv:2303.05153.![]()

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。