Please select your location and preferred language where available.
ディープラーニング用のAIプロセッサを開発し半導体回路の国際学会A-SSCC2018で発表しました*。
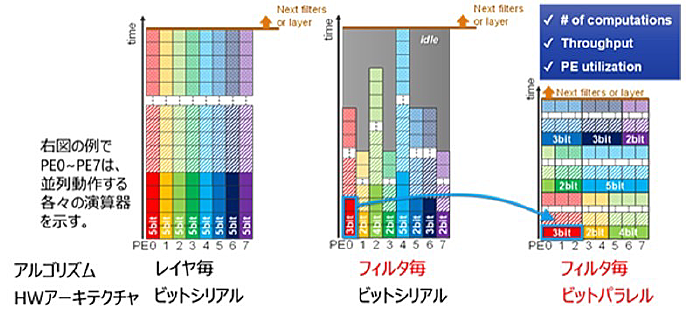
ディープラーニングでは大量の積和演算を行う必要がありますが、演算の処理時間や消費エネルギーが大きいという課題にたいして、今回導入した主な新技術は、「フィルターごとの最適量子化アルゴリズム」(図1)と「ビットパラレル方式積和演算器」(図2)です。
まず図1下に示すように積和演算で用いる定数(重み)のビット数を、ニューラルネットワークの各レイアに数十~数千あるフィルタ毎に、別々の最適ビット数を割り当てる手法を開発しました。平均ビット精度を3.8ビットにすると認識精度が50%以下に劣化する「レイヤーごとの最適量子化」(図1中央)に比べ、フィルタ毎の最適量子化(図1下)では平均ビット精度を3.6ビットまで削減しても、認識精度をほとんど劣化させずに、演算量が更に削減できます。

また積和演算器のアーキテクチャとして採用されることの多いビットシリアル方式を前記のフィルター毎のビット数最適化に適用した場合(図2中央)、演算量が大きいフィルターを受け持つ演算機(PE: Processing Element )がボトルネックとなり、「待ち」が発生することが考えられますが、ビットパラレル方式(図2右)では、1ビットに分解し各演算器に順番に割り当てて並列動作させることで演算器の利用効率はほぼ100%に高まり、スループットを高めることが出来ます。
今回開発した技術を用いて、ResNet-50*1のニューラルネットワークをFPGA*2に実装し、ImageNet*3を用いた画像認識のテストで、認識精度をほとんど劣化させずに演算スループットを約5.3倍改善、演算時間と消費エネルギーを従来の18.7%まで削減できることを確認しました。
- ResNet-50:画像認識用のディープラーニングでよく用いられるニューラルネットワークのモデル。ハードウエアのベンチマークにも用いられる
- FPGA(Field Programmable Gate Array):チップ製造後にプログラム可能なロジックLSI
- ImageNet:一般的に画像認識のベンチマークで用いられる大規模な画像データセットのひとつ

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。