Please select your location and preferred language where available.
基盤モデル*1(Foundation Model)は、大規模なデータで学習されたモデルであり、一つのモデルで様々な種類の高精度予測が可能であることから、最近では深層学習分野で重要な役割を果たしています。基盤モデルを適切に活用することにより、高コストな独自モデルの学習を実施しなくても、アプリケーションのパフォーマンスを向上させることができます。画像検索は、オンラインショッピング、データ管理、知識管理など、さまざまな場面で応用される需要の高い技術です。基盤モデルをベースにした画像検索は、追加学習なしでも機能しますが、ユーザーの好みに応じた検索結果を提供することができない場合があります。
*1 基盤モデルは、大規模なデータで学習され、自然言語処理や画像生成など、一般的なさまざまのタスクに適応できる深層学習ニューラルネットワークです。
上記課題を解決するために、本研究は、基盤モデルをベースにした画像検索において、さまざまなユーザーの好みに応じた検索結果を提供することを目指します。我々は、画像処理に高性能な基盤モデルの一つであるCLIP[2]を利用したインタラクティブな画像検索アルゴリズムを提案します。ここでは、ユーザーのフィードバック収集方法の一つである適合性フィードバックを利用して、ユーザーの好みを取得します。
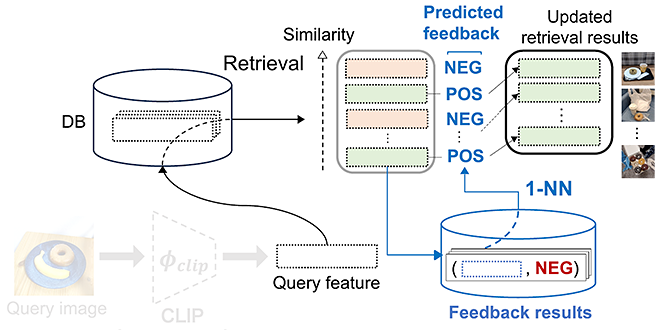
提案手法はまず、基盤モデルに基づいてデータベースの中からクエリ画像と類似していると判断された検索結果画像を表示します。その後、上位ランクの検索結果画像のみに対して、ユーザーからフィードバック(ユーザーの好みに合うか合わないか)を取得し、保存します(図1参照)。そして、最近傍予測器(1-NN、1-Nearest Neighbor predicator の略)がフィードバック結果(Feedback results)を利用し、ユーザーの好みを学習します(図 2 参照)。さらに最近傍予測器は検索結果画像それぞれに対し、図1で示すユーザーがフィードバックしたどの画像に似ているかを判別することで、当該画像がユーザーの好みに合うか合わないか(予測フィードバック)を判断します。
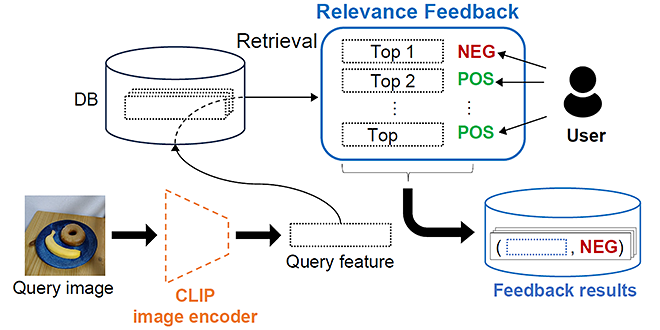
図2に示すように、基盤モデルがクエリ画像と類似していると判断した検索結果画像を最近傍予測器(1-NN)でフィルタリングすることで、最終的にユーザーの好みに合うと予測された検索結果のみを出力します。補足ですが、ここでは図1で得られた検索結果を図1のフィードバック結果を用いてフィルタリングしてユーザーの好みに合わせています。しかし、図1とは異なる検索結果を図1のフィードバック結果を用いてフィルタリングしてユーザーの好みに合わせることも可能であり、フィードバック結果は複数の検索に再利用することができます。
提案手法の有効性を示すために、異なるユースケースを想定した以下の三つの評価タスクを実施しました。(1)ユーザーはクエリ画像と同じ種類のオブジェクトを含む画像を望むケース(例:クエリ画像に「ドーナツ」と「バナナ」が存在し、ユーザーが「ドーナツ」を含む画像を望んでいて、「バナナ」のみの画像を望まないケース)、(2)ユーザーはクエリ画像と同じ特定の属性を持っているオブジェクトを含む画像を望むケース(例:クエリ画像に「光沢のある靴」が存在し、ユーザーが「光沢のある靴」を望んでいて、「光沢のない靴」を望まないケース)、(3)ユーザーはクエリ画像と同じオブジェクトを含む、かつ一部の属性が修正された画像を望むケース(例:クエリ画像には「きれいな服」が存在し、ユーザーが「汚い服」を望んでいて、「きれいな服」を望まないケース)。
提案手法が三つすべてのタスクで良い性能を達成することが確認されています。例えば、表1は、異なるデータセット[3][4][5]において、ユースケース(2)のRecall@1性能(ランク1位の検索結果画像が正解である割合)が提案手法によって向上することを示しています。(数字が大きいほうが性能が良い)
※表を左右にスクロールすることができます。
| Approach | Dataset | ||
|---|---|---|---|
| Fashion-200k | MIT-States | COCO | |
| CLIP | 66.1 | 37.9 | 49.7 |
| Ours | 74.3 | 47.1 | 58.4 |
提案された手法により、基盤モデルCLIPと適合性フィードバック技術を活用し、汎用的にユーザーの好みにより合う画像検索結果を提供することに成功しました。
本研究は東京大学と共同で研究しました。
この資料は文献[1]の一部引用および再構成です。©2024 Springer.
企業名、製品名、サービス名は、第三者企業の商標である場合があります。
本成果は、ECCV 2024学会の併設ワークショップ Workshop on Traditional Computer Vision in the Age of Deep Learning(TradiCV)で発表されました[1]。
文献
[1] R. Nara, et al. “Revisiting Relevance Feedback for CLIP-based Interactive Image Retrieval”, Computer Vision – ECCV Workshops, 2024.
[2] A. Radford, et al. “Learning transferable visual models from natural language supervision”, International conference on machine learning (ICML). PMLR, 2021.
[3] X. Han, et al. “Automatic spatially-aware fashion concept discovery”, Proceedings of the IEEE international conference on computer vision (ICCV). 2017.
[4] P. Isola, et al. “Discovering states and transformations in image collections”, Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2015.
[5] T.Y. Lin, et al. “Microsoft coco: Common objects in context”, Computer Vision – ECCV 2014.

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。