Please select your location and preferred language where available.
近年、ChatGPTをはじめとする大規模言語モデル(LLM (Large Language Models) )を用いたチャット形式のAIサービスやアプリケーションが普及し、日常生活や日々の業務の中でも取り入れられています。LLMの中には、テキストで表された言語の情報のみならず、画像や映像内に写った情報を解釈し、処理することができるマルチモーダルLLM(以下、M-LLM*1と呼びます)が登場しています。当社は画像検索の用途向けにM-LLMを活用した技術を開発しました。本記事ではその研究成果[1]をご紹介します。
*1 Multi-modal LLM。画像や音声など、テキスト以外の複数のモダリティ(様式)のデータにも対応した大規模言語モデル。
画像検索の技術は、インターネットで画像を探す際や個人のスマートフォン内の写真を探す際など、日常的にも用いられています。画像検索の方法の1つにキーワード検索があります。例えば、ユーザーが画像を探す際に「車」や「猫」といった単語をキーワードとして入力することで、データベースの中からキーワードに関連する画像を探し出すことができます。
キーワード検索では、検索結果を踏まえてキーワードを修正したり、新しいキーワードを追加して条件を絞り込んだりすることが簡単にできます。ただし、画像と言語は本来、互いに独立した異なる形式(様式)で表現された情報であるため、テキストデータに基づき画像をキーワード検索できるようにするには、画像データと関連するテキストデータを結び付けてデータベースに保存するという人手のアノテーション作業が必要であり、課題となっていました。
近年の深層学習の研究では、インターネットから収集した数億枚以上の画像データとテキストデータの組*2を照らし合わせ、写真等の画像が持つ意味とテキストで表された言語的な意味の結び付き(関連性)を学習する技術が開発されています[2][3]。このような深層学習の技術を用いることで、人手のアノテーション作業を介さずとも、画像とテキスト同士の意味的関連性を距離(数値)として測ることが可能となります。この距離計算に基づき、入力されたテキストの意味に関連した画像を検索できるようになるため、近年の画像検索の研究では引用文献[2][3]の技術を発展させた方法が盛んに開発されています。しかし、先に述べたキーワード検索のように、検索結果を踏まえての修正や追加など、条件の絞り込みができないため、万能というわけでもありません。
*2 インターネットから収集された画像データとテキストデータの組の例としてはWebページ上の画像とその代替テキスト(Alternative text)やSNS投稿画像と付随するハッシュタグなどが挙げられる。
一方で、M-LLMが登場した昨今においては、画像内に含まれる情報をテキストデータとして取り出すことも可能になりました。図1にM-LLMを活用した当社の画像検索の方式を示します。図1の方式では、例えばM-LLMに入力する画像とともに「この画像の特徴をタグや文で表現してください」というプロンプト(指示)を入力することで、「鳩」や「橋」といった画像内に含まれる情報をテキストで取り出せます。画像内の情報がテキストで表現されることで、文書検索用のアルゴリズムを活用することができます。
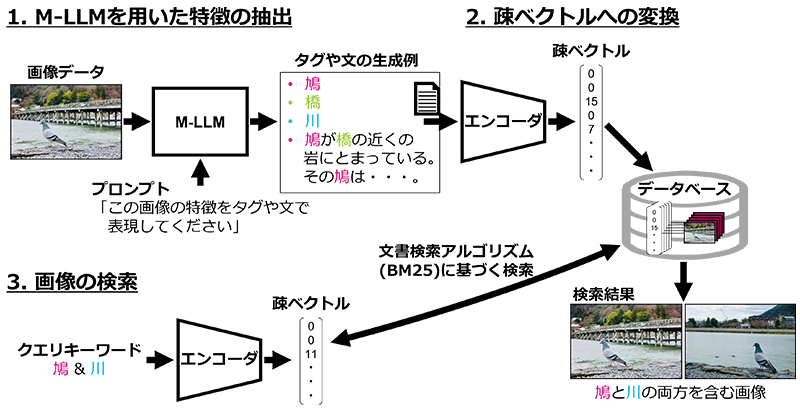
これらの状況を踏まえ、今回我々は、実用的な画像検索の方法であるキーワード検索に再注目し、文書検索に用いられるBM25*3アルゴリズムを活用することで、自然言語処理*4の視点から画像検索の性能を向上できることを示しました。
*3 Best Match 25。文書検索に用いられる情報検索アルゴリズムの1つ。文書中の単語の出現頻度や文書の長さなどの情報を考慮し、クエリと文書のマッチング度合いを評価して順位付けを行う。
*4 人間が使用する日本語や英語などの言語情報を、テキストや音声などのデータとしてコンピュータで解析し処理する技術。
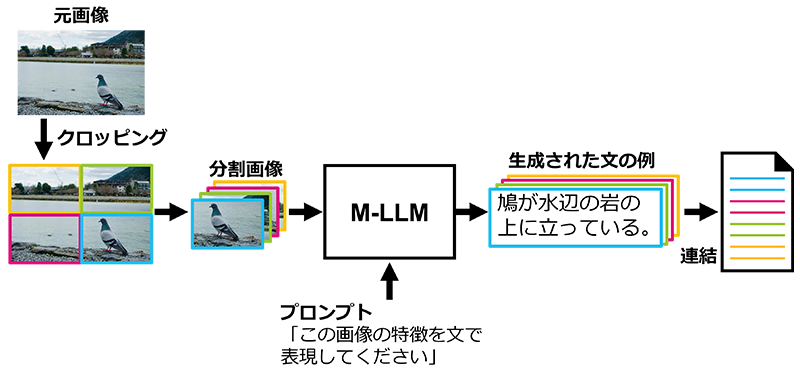
その際、M-LLM活用の課題への対策も行いました。M-LLMを用いて画像内の情報を取り出す際、元々の1枚の画像全体をM-LLMに入力するとM-LLMが注目すべき範囲が広くなり、画像の細部に写った情報を取りこぼすという課題がありました。そこで、当社は画像を分割するクロッピングという技術を利用しました(図2)。クロッピングはデータ拡張手法の1つであり、例えば、画像分類問題において教師データを水増しするために用いられます。今回、我々は元々の1枚の画像全体だけでなく、クロッピングにより分割された各画像もM-LLMに入力することで、M-LLMが注目すべき範囲を絞りつつ、画像の細部に写った情報の取りこぼしも防ぐことで検索性能の向上を図りました。
キーワード検索の場面を想定し、当社の方式の検索性能を評価しました。検索の精度を表す指標には適合率(Precision)と再現率(Recall)があり、両者の関係を表したPR (Precision-Recall) 曲線を図3に示します。精度評価には画像検索の評価に用いられるデータセット(MS-COCO[4]、PASCAL VOC[5])を使用し、各画像に設定されている教師ラベルをクエリキーワードとして設定し、対応する画像をいかに精度よく検索できるかを評価しています。
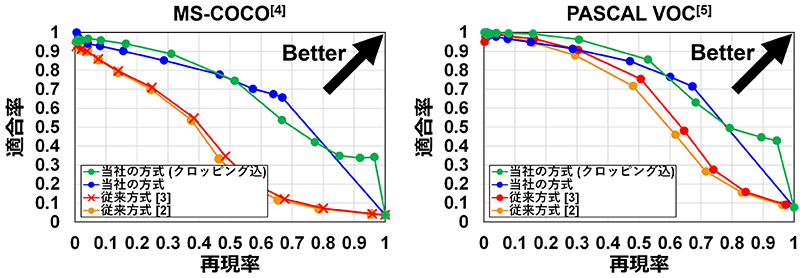
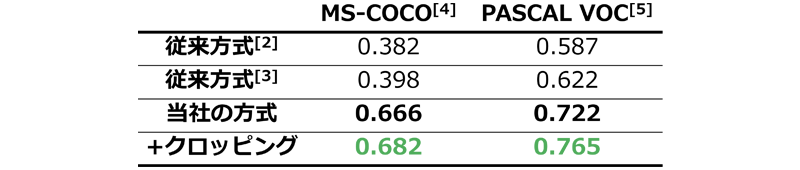
図3から当社の方式はPR曲線のグラフにおいて、従来方式[2][3]よりも右上に位置し、優位性を確認できます。また、適合率と再現率の関係を定量的に評価するための指標であるPR-AUC (Area Under the Precision-Recall Curve:PR曲線のグラフ下の面積) の値を見ても、当社の方式は従来方式よりも優れています(表1)。表1からはクロッピングの技術を用いることによる改善効果も確認でき、今回検討した画像検索の方式がキーワード検索の場面において有効であると示せます。
本成果は2024年9月に開催されたコンピュータビジョン分野のトップの国際会議の1つであるECCV 2024 (European Conference on Computer Vision 2024) に併設のTradiCVワークショップ*5で発表されました[1]。
*5 2nd Workshop on Traditional Computer Vision in the Age of Deep Learning
本稿は、文献[1]©2024 Springerから図面等一部抜粋&再構成したものです。
記載されている社名・商品名・サービス名などは、それぞれ各社が商標として使用している場合があります。
文献
[1] K. Nakata, D. Miyashita, Y. Ng, Y. Hoshi, J. Deguchi, “Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models”, Computer Vision – ECCV Workshops, 2024.
[2] A. Radford, et al, “Learning Transferable Visual Models From Natural Language Supervision”, ICML, pp.8748-8763, 2021.
[3] C. Jia, et al, “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, ICML, pp.4904-4916, 2021.
[4] T. Y. Lin, et al, “Microsoft COCO: Common Objects in Context”, Computer Vision – ECCV, pp.740-755, 2014.
[5] M. Everingham, et al, “The Pascal Visual Object Classes Challenge: A Retrospective”, IJCV, pp.98-136, 2015.

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。