Please select your location and preferred language where available.
グラフ処理は、SNSでのリコメンデーションやフェイクニュース検知に用いるソーシャルネットワーク解析、コンピュータネットワーク解析さらにゲノム解析など様々な用途で活用されている最も重要なデータ処理の一つです。ビッグデータを扱う現代においては、扱うグラフサイズが非常に大規模となってきています。グラフサイズが大きくDRAMに収まらない場合、SSDを活用する方法が知られています。しかし、数バイトから数百バイトの細かい粒度でのランダム読み出しが多数含まれるグラフ処理アルゴリズムは、従来のSSDでは高速に処理することができませんでした。例えば、単にSSDを仮想メモリーとして用いるとDRAMアクセスの約1/100の速度に、さらに、ソフトウェアでアクセスを最適化しても約1/10の速度となってしまします。我々は高速なフラッシュメモリ(XL-FLASH™) [1]を用いるとともに新しいアクセス方式を開発し、全てのデータをDRAMに収めるのと同等の速度を達成しました。これにより、超大容量で高速なグラフ処理をDRAMより低コストのフラッシュメモリで実現可能となります。この成果はVery Large Data Base VLDB2021で発表されました[2]。
以下に技術詳細を記載します。
当社で開発している低レイテンシフラッシュメモリ XL-FLASH™を適用し、従来の SSD より一桁多いランダム読み出しアクセス性能を実現したドライブ(図1)を用います。
XL-FLASH™ を用いることで、1 秒あたりに処理できるランダム読み出しアクセス数が、従来の SSD より一桁多くなり高速な処理が可能となります。しかし、アクセス数が増えることにより、アクセスリクエスト発行・完了確認のためのCPU処理時間の割合が増えるため、1 アクセスあたりのリクエスト発行・完了確認のCPU処理時間を低減することが重要となります。そのために私たちは、2つの技術を用いたCPUのリクエスト処理時間を低減するアクセス方式を開発しました。1つ目は、既存の SSD のインタフェースである NVMe™ IFプロトコルのCPU処理時間を低減するプロトコルです (図2)。そして2つ目は、XL-FLASH™のデータ読み出しを待つ間に CPUが他の処理をするための切り替え時間(コンテキスト切替時間)を低減する方式です。これらにより、1アクセスあたり10ns未満のCPU負荷で読み出しアクセスを処理できます(図3)。



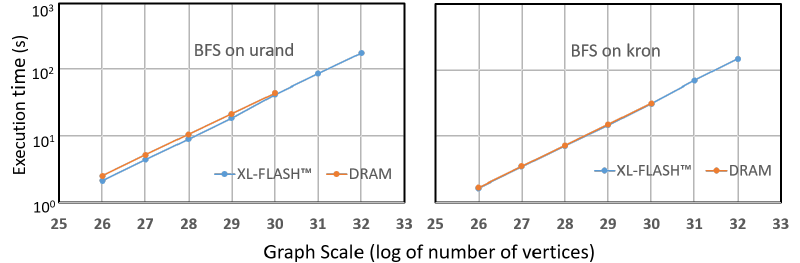
これらの大規模グラフ処理への適用評価のため、グラフデータの大部分をXL-FLASH™上に置いた場合と、全てのデータをDRAM上に置いた場合との2つの環境での実行時間を比較しました(図4)。その結果、典型的なグラフ処理である、グラフ上の幅優先探索(BFS)などの処理において、両者は同等な時間で実行可能であることを示しました。また、XL-FLASH™を用いたシステムは DRAMでは保持できないくらい大きなグラフサイズにおいても、大幅に実行時間が増えることなく処理ができます。本結果は、提案するアクセス方式をグラフ処理に適用した一例ですが、大規模なデータに対してランダムアクセスを行うグラフ処理以外のアプリケーションに対しても適用可能であると考えています。
本稿は、2021年8月に開催されたVLDB2021で発表された文献[2]から図面等一部抜粋&再構成したものです。
NVMe は、NVM Express, Inc. の米国またはその他の国における登録商標または商標です。
PCIe は、PCI-SIG の登録商標です。
その他記載されている社名・商品名・サービス名などは、それぞれ各社が商標として使用している場合があります。
[1] Kioxia press release, August 5, 2019
http://americas.kioxia.com/en-us/business/news/2019/memory-20190805-1.html![]()
[2] T. Suzuki et al., Approaching DRAM performance by using microsecond-latency flash memory for small-sized random read accesses: a new access method and its graph applications. Proceedings of the VLDB Endowment 14, 8 (2021), 1311 - 1324

半導体メモリやSSDなど、キオクシアの製品や技術に関わる用語を取り上げた技術用語集です。技術者・研究者の方から一般の皆さままでご活用いただけるよう解説しています。

キオクシアでは「記憶」の技術で業界をリードする研究・技術開発体制を敷いています。各拠点を活用し、 オープンイノベーションを推進しながら技術革新を行っています。