Please select your location and preferred language where available.
Development of Image Retrieval System Utilizing a Multi-modal Large Language Model
January 28, 2025
Recently, AI services and applications that utilize large language models (LLMs), such as ChatGPT, have gained popularity and are widely used in daily life for various tasks. Furthermore, multi-modal LLMs (M-LLMs) have already been developed, which can comprehend and process not only textual information but also visual information within images and videos. Kioxia has developed an image retrieval system utilizing M-LLM. We present the system and our research findings[1].
Image retrieval technology is commonly used in daily life, such as when searching for images on the internet or looking for photos within a personal smartphone. One practical application of image retrieval is keyword-based retrieval. For example, when users search for images, they can input text as query keywords (e.g., “car” or “cat”) to find images related to the query keywords from the database. In keyword-based retrieval, users can easily modify query keywords and add new keywords to narrow down the search conditions based on the retrieval results. However, images and texts are independent pieces of information represented in different modalities. For keyword-based retrieval, human annotation is necessary to associate related images and texts with each other and store them in the database.
Recent research on deep learning has developed a contrastive learning scheme that learns vision-language representations and the semantic relationship between images and texts by aligning hundreds of millions of image-text pairs collected from the internet. By utilizing a model trained using this learning method, the semantic relationship between images and texts can be calculated as a distance. Based on this distance calculation, images that are semantically related to the input text can be retrieved from the database without the need for human annotation. Due to their remarkable performance, image retrieval approaches utilizing such learning methods have been actively developed in image retrieval research. However, unlike keyword-based retrieval, these approaches are not universal solutions as they cannot narrow down the search conditions by modifying query keywords or adding new keywords based on the retrieval results.
On the other hand, with the recent emergence of M-LLMs, it has become possible to extract information contained in images as textual data without human annotation. We present our image retrieval system that utilizes an M-LLM in Figure 1. For example, we provide the M-LLM with an image and a prompt such as “Please describe the features of this image in tags and captions.” Then, the M-LLM can extract information such as “pigeon” or “bridge” from the image. By extracting the information within images as textual data, we can utilize algorithms for document retrieval.
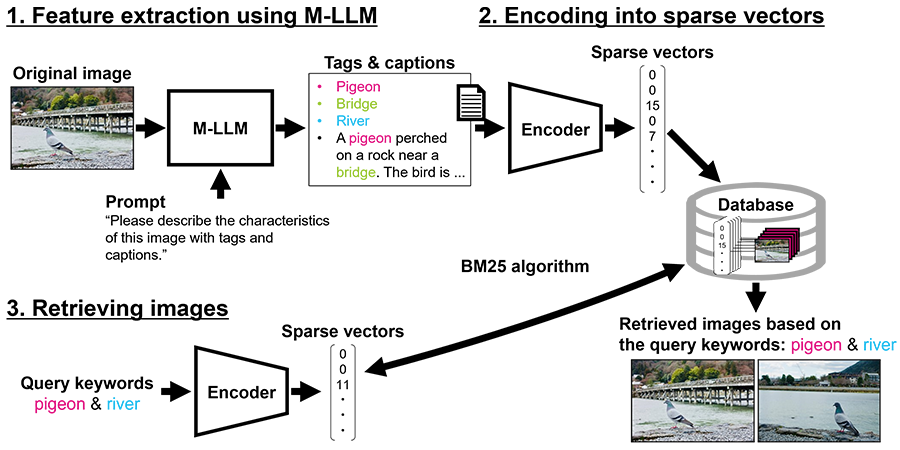
Based on the above situation, we have re-focused on keyword-based retrieval, which is a practical approach for image retrieval. We utilize the BM25 algorithm*1, which is used for document retrieval, and empirically demonstrate the performance improvement on image retrieval tasks from the perspective of natural language processing.
*1 Best Match 25 algorithm evaluates the relevance of documents to a given search query. BM25 calculates a relevance score for each document based on the frequency of query terms within the document and the inverse document frequency (IDF) of those terms across the entire document collection.
Furthermore, we also addressed the issue of effectively utilizing M-LLMs. When extracting information from an image using an M-LLM, we encountered a problem where the M-LLM would focus on a wide range of the image, resulting in information loss of details captured in the image. In our approach, we employ a cropping technique to effectively extract information within images (Figure 2). The cropping technique is one of the data augmentation techniques used in image classification tasks to increase the amount of training data. We divide an original image into multiple segments as cropped images, and the M-LLM generates corresponding captions that describe the features of each cropped image. This allows the M-LLM to focus on specific areas of interest and prevent the information loss of details captured in the original image, leading to improved retrieval performance.

We evaluated the retrieval performance for our image retrieval system in a keyword-based retrieval scenario. As the evaluation metric, we evaluated the precision and recall performance, illustrating their relationship through the PR (Precision-Recall) curves presented in Figure 3. To conduct the evaluation, we utilized the MS-COCO[4] and PASCAL VOC[5] datasets, which are commonly employed for evaluating image retrieval tasks.
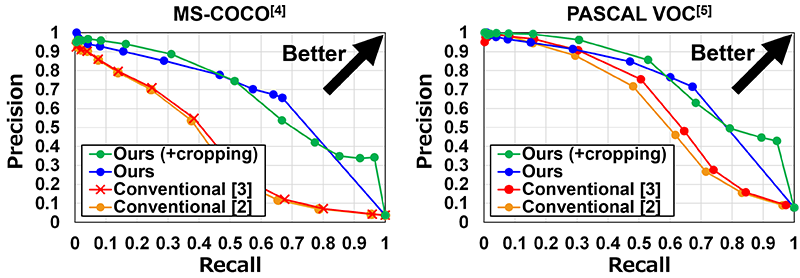
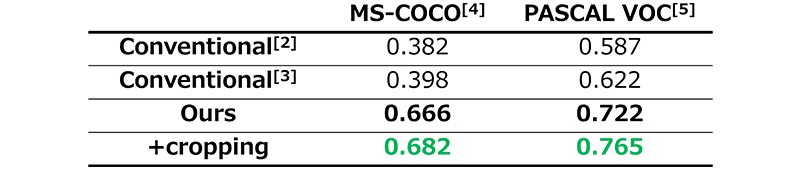
We used the ground-truth labels as query keywords and verified whether the corresponding images could be accurately retrieved. As shown in the PR curves of Figure. 3, our approach outperforms the conventional ones[2][3]. In addition, the values of PR-AUC (Area Under the Precision-Recall)*2 are superior to those achieved by the conventional approaches, as shown in Table 1. Table 1 also demonstrates the improvement in retrieval performance when using the cropping technique, thus validating the effectiveness of our image retrieval system in the keyword-based retrieval scenario.
*2 PR-AUC is a commonly employed quantitative metric used to evaluate retrieval performance based on both precision and recall.
This achievement was presented at 2nd Workshop on Traditional Computer Vision in the Age of Deep Learning (TradiCV), in conjunction with European Conference on Computer Vision 2024 (ECCV 2024)[1].
This material is a partial excerpt and a reconstruction of Ref [1]©2024 Springer.
Company names, product names, and service names may be trademarks of third-party companies.
Reference
[1] K. Nakata, D. Miyashita, Y. Ng, Y. Hoshi, J. Deguchi, “Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models”, Computer Vision – ECCV Workshops, 2024.
[2] A. Radford, et al, “Learning Transferable Visual Models From Natural Language Supervision”, ICML, pp.8748-8763, 2021.
[3] C. Jia, et al, “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, ICML, pp.4904-4916, 2021.
[4] T. Y. Lin, et al, “Microsoft COCO: Common Objects in Context”, Computer Vision – ECCV, pp.740-755, 2014.
[5] M. Everingham, et al, “The Pascal Visual Object Classes Challenge: A Retrospective”, IJCV, pp.98-136, 2015.

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.