Please select your location and preferred language where available.
Image Retrieval Reflecting User Preferences
April 21, 2025
Foundation models*1, which are trained on various data at scale, have been playing an important role in the deep learning field nowadays due to their high prediction accuracy. Properly utilizing the foundation models is able to improve applications’ performance, without spending high-cost resource in specific model training. Image retrieval is a highly-demanded technique which can be found applied in various systems such as e-commerce, data management, and knowledge management. Built with foundation models, image retrieval can generally function well without extra training cost, but it is usually lack of the ability to customize retrieval results according to user’s preferences.
*1 Foundation model: A foundation model is a deep learning neural network which is trained on a huge amount of data and is able to be adapted to various general tasks such as natural language processing and image generation.
This research is to make foundation-model-based image retrieval able to handle various user’s preferences. We propose an interactive image retrieval solution, which utilizes CLIP[2], one of the high performance visual foundation models, for image processing, and we utilize relevance feedback, one of the user feedback gathering methods, for user’s preference collection.
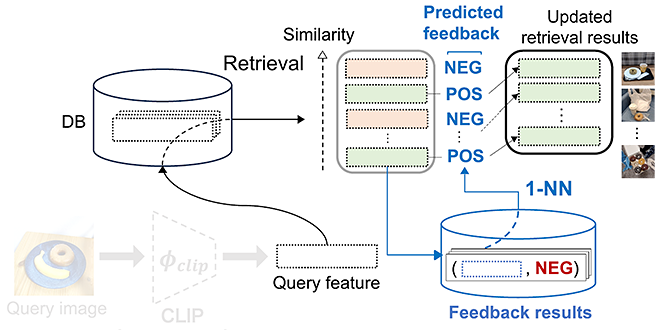
The system first displays the images, which are retrieved from the database and are determined similar to the query image based on the foundation model. Then the system gets feedback (i.e., whether the retrieved image is what user prefers) of top-ranked retrieved images from the user, as shown in Figure 1. Based on the collected feedback, the system learns user’s preference by building a nearest-neighbor predictor (1-NN, short for 1-Nearest Neighbor predicator), as shown in Figure 2. For each retrieved image, the nearest-neighbor predictor finds the nearest image in the result feedback database shown in Figure 1, and judges whether the retrieved image is what user prefers based on the collected feedback of the nearest image.
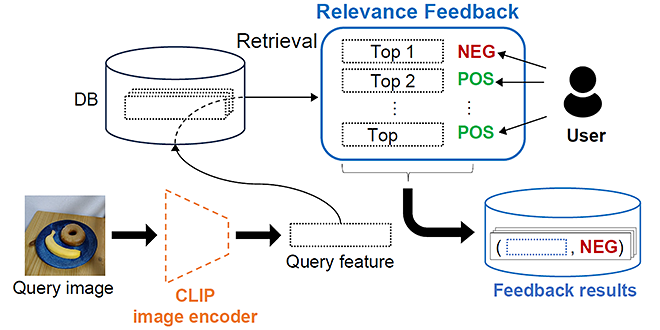
As shown in Figure 2, the system can align the retrieval results to user’s preference by utilizing the learned nearest-neighbor predictor (1-NN) to filter out the less favored images. In the explanation above, feedback collected in Figure 1 is used for filtering images retrieved from the same database. However, it is worth noting that feedback collected in Figure 1 can also be used for filtering images retrieved from other similar database, i.e., DB in Figure 2 can be similar to but different from DB in Figure 1, implying reusability of the collected feedback.
To demonstrate the effectiveness of the proposed, we carefully execute three evaluation tasks, representing different use cases with various user preferences: (1) the user wants images containing the same kind of object as in the query image (e.g., a donut and a banana are in the query image, and the user prefers images with any donut in them but dislikes images with only banana in them); (2) the user wants images containing an object sharing a specific property with the query image (e.g., shiny shoes are in the query image, and the user prefers shiny shoes but dislikes dim shoes); (3) the user wants images containing the same object as in the query image while some property revised (clean clothes are in the query image, and the user prefers dirty clothes but dislikes clean clothes).
It is empirically verified that the proposed system achieves competitive performance on all three tasks. For example, Table 1 shows that the proposed method improves the Recall@1 (i.e., the percentage that the top-ranked image is actually required) of the use case (2) on different datasets[3][4][5].
* Table can be scrolled horizontally.
| Approach | Dataset | ||
|---|---|---|---|
| Fashion-200k | MIT-States | COCO | |
| CLIP | 66.1 | 37.9 | 49.7 |
| Ours | 74.3 | 47.1 | 58.4 |
With the proposed approach, we successfully leverage the foundation model CLIP and relevance feedback technique to in general provide image retrieval results better aligned to user’s preferences.
This research is in collaboration with the University of Tokyo.
This material is a partial excerpt and a reconstruction of Ref. [1] ©2024 Springer.
Company names, product names, and service names may be trademarks of third-party companies.
This achievement was presented at Workshop on Traditional Computer Vision in the Age of Deep Learning (TradiCV), in conjunction with European Conference on Computer Vision 2024 (ECCV 2024)[1].
Reference
[1] R. Nara, et al. “Revisiting Relevance Feedback for CLIP-based Interactive Image Retrieval”, Computer Vision – ECCV Workshops, 2024.
[2] A. Radford, et al. “Learning transferable visual models from natural language supervision”, International conference on machine learning (ICML). PMLR, 2021.
[3] X. Han, et al. “Automatic spatially-aware fashion concept discovery”, Proceedings of the IEEE international conference on computer vision (ICCV). 2017.
[4] P. Isola, et al. “Discovering states and transformations in image collections”, Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). 2015.
[5] T.Y. Lin, et al. “Microsoft coco: Common objects in context”, Computer Vision – ECCV 2014.

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.