Please select your location and preferred language where available.
GPU Graph Processing on CXL™-Based Microsecond-Latency External Memory
March 06, 2024
GPUs have become one of the most commonly-used accelerators in high-performance computing (HPC) and machine learning. There are some GPU applications whose data cannot fit in GPU memory. For this reason, external memory such as CPU-attached DRAM (host DRAM) or SSDs have been used.
In this study, we evaluated the use of recently introduced Compute Express Link™(CXL) as external memory for GPUs. CXL is a standard interface that mainly connects the CPUs and memory devices. As shown in Figure 1, CXL uses the physical layer of PCI Express, so it can be added later, like GPUs or network cards. In addition, CPUs and GPUs can use the memory connected by CXL (CXL memory) in the same way as host DRAM.

CXL memory introduces additional latency to the underlying memory devices, and an added latency of one or two hundred nanoseconds is shown to already have an adverse performance impact on some of CPU applications[1]. However, there were no existing studies that evaluated the impact of additional latency on GPU applications.
Therefore, we evaluated the latency impact of CXL on GPU applications using real devices[2,3]. Our analysis showed that GPU applications are tolerant of latency. We also explored the possibility of using memory modules such as low-latency flash, which has a latency of a few microseconds.
We selected graph processing as the GPU application for this study. Graph processing performance is one of the key metrics in HPC and is used as a performance indicator in the Graph500![]() supercomputers ranking. Graph processing requires hundreds of GB of memory in some cases and is frequently used in external memory studies. Its access to external memory is fine-grained and it is suitable as an application to see latency impact.
supercomputers ranking. Graph processing requires hundreds of GB of memory in some cases and is frequently used in external memory studies. Its access to external memory is fine-grained and it is suitable as an application to see latency impact.
For the evaluation, we implemented a latency adjustment feature on a CXL-enabled FPGA device (Intel Agilex®7) as shown in Figure 2. This feature emulates CXL memory with a few microseconds latency. In addition, the latency is not fixed, but can be changed.
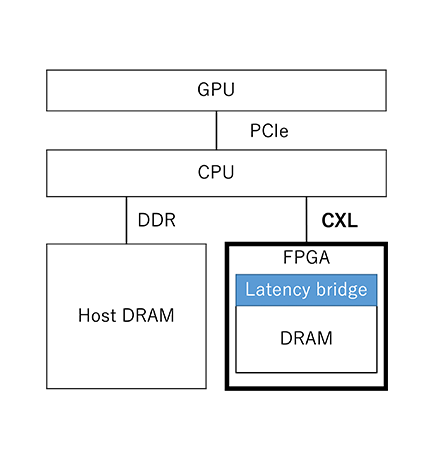



Figure 3 shows graph processing time with CXL memory. The vertical axis shows the execution time on the CXL memory normalized by that on the host DRAM. The horizontal axis shows the access latency to CXL memory varied by the latency adjustment feature. We use Breadth First Search (BFS) and Single Source Shortest Path (SSSP) as algorithms for graph processing. The results show that as long as the CXL memory latency from the GPU is under around 2μs, the execution time on CXL memory is almost identical to that on the host DRAM.
We have demonstrated GPU graph processing speeds close to using the host DRAM when the CXL memory latency is under a few microseconds. This is an initial evaluation of CXL memory with long latency, and we hope this will lead to CXL memory equipped with flash memory in the future.
This achievement was presented at the international workshop MTSA, SC23.
Reference
[1] H. Li et al. Pond: CXL-Based Memory Pooling Systems for Cloud Platforms. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2023.
[2] S. Sano, Y. Bando et al. GPU Graph Processing on CXL-Based Microsecond-Latency External Memory. Proceedings of the SC '23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis
[3] S. Sano, Y. Bando et al. GPU Graph Processing on CXL-Based Microsecond-Latency External Memory. ![]()

A technical glossary that covers terms related to KIOXIA products and technologies, such as memory and SSDs. We explain that it can be used by engineers and researchers to the general public.

KIOXIA has established industry-leading R&D frameworks with “memory” technology. We use our various locations to conduct technological innovation while promoting open innovation.